研究室内メモ. 論文紹介.
環境: macOS Sierra 10.14.2, CPU: 3.3 GHz Intel Core i5, Memory: 8 GB. Python 3.6.4, PyTorch 1.0.1, NumPy 1.14.2, RDKit 2018.03.1, KNIME Analytics Platform v3.7.1.v201901281154.
“QBMG: quasi-biogenic molecule generator with deep recurrent neural network”
Zheng, S.; Yan, X.; Gu, Q.; Yang, Y.; Du, Y.; Lu, Y.; Xu, J.* J. Cheminform. 2019, 11, 5.
著者らはゲート付き回帰型ユニット(gated recurrent unit: GRU)回帰型ニューラルネットワーク(recurrent neural network) を使って天然物ライクなバーチャル化合物ライブラリーの生成を行った.本手法ではCanonical SMILESを入力とすることで,立体化学的性質を取り入れている.転移学習(transfer learning)と組み合わせることで,特定の骨格(論文の例はクマリン)を持つバーチャル化合物ライブラリーの生成も可能.
Contents
コード
https://github.com/SYSU-RCDD/QBMG からダウンロード.
用語メモ
SMILES
SMILES (Simplified molecular input line entry system): 化合物構造の表記法.化合物構造を幹と枝で表わし,環を巻く位置は数字のペアで指定する.
例えば “CCCCCC” はn-hexaneで, “C1CCCCC1” はcyclohexane, “C1(CO)CCCCC1” はcyclohexylmethanolとなる.
ある化合物に対して複数のSMILES文字列を割当てることが可能である.例えば,CCO, OCC, およびC(O)Cはいずれもethanolに対するSMILES文字列となる.任意の分子に同一のSMILES文字列を生成するアルゴリズムが開発されていて,このアルゴリズムで生成された文字列を “Canonical(正準) SMILES” と呼ぶ.立体化学情報を含んだ文字列は “Isomeric SMILES” と呼ばれる.
立体化学を含む例: (2R)-2-Amino-2-phenylethanolのIsomeric SMILESは “C1=CC=C(C=C1)[C@H](CO)N”,(2S)-2-Amino-2-phenylethanolのIsomeric SMILESは “C1=CC=C(C=C1)[C@@H](CO)N”.
回帰結合型ニューラルネットワーク
回帰結合型ニューラルネットワーク (recurrent neural network) は,順番に意味があるデータ(文章や時系列データなど)を入力に取って,文章であれば単語間のつながりを学習できる.機械翻訳や音声認識に応用されて成功を収めている.本論文の場合は,文章で例えるならば,文の代わりにSMILESを入力するので,”C”,”1″,”=”,”[C@@H]” などがそれぞれ「単語」となる.
転移学習
既存の学習済モデル(出力層以外の部分)を、重みデータは変更せずに特徴量抽出機として利用する。
Tokenization
SMILES文字列を「単語 = token」に分解して,Tokenベクトルに変換する工程.論文ではTokenの種類は87種類なので,任意のTokenは長さ87のOne-hotベクトル(1つだけ値が1で残りが全て0のベクトル)として表現され,文字列はOne-hot行列として表現される.これはメモリを大幅に食うため,論文ではこの行列を自然言語処理で使われるword embedding法を応用して,情報が豊かなword embedding行列へと変換してから,ネットワークに入力している.
コードの修正
CPU上で動かすのと,PyTorchのバージョンが違うのが理由でエラーが出るため,エラーにしたがって以下のように修正しました.
transfer-learning.pyの25行目とsample.pyの18行目
Prior.rnn.load_state_dict(torch.load(restore_from))
を
Prior.rnn.load_state_dict(torch.load(restore_from, map_location=cpu))
に修正.transfer-learning.pyの49行目
tqdm.write("Epoch {:3d} step {:3d} loss: {:5.2f}\n".format(epoch, step, loss.data[0]))
を
tqdm.write("Epoch {:3d} step {:3d} loss: {:5.2f}\n".format(epoch, step, loss.item()))
に修正.
Quasi-biogenic moleculesの生成
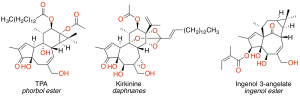
論文では無料の化合物構造データベースZINCのbiogenic compounds 153,733構造を使ってRNNを訓練して,転移学習ではクマリン骨格を持つ化合物2239種類を使っていました. 今回はphorbol estersとdaphnanesとingenol esters(とそれらのアナログ)合わせて212化合物 (test.smiとしてdataフォルダに保存) を使って転移学習と構造の生成を行ってみました.
(>anaconda3-5.1.0)> $ python transfer_learning.py ./data/test.smi
100 epochsの学習は17分30秒で終了しました.Valid SMILESの割合は,10 epochsで94%,後は96.0–100.0%の間でした.
次に保存された ./data/100_epochs_transfer.ckpt を使って構造の生成を行いました(test.ckptとしてコピーしておく). コマンドの最後の数字が生成する構造の数です.
(>anaconda3-5.1.0)> $ python sample.py ./data/test.ckpt 1000
4分37秒で終了し,sample.smiファイルが生成されました.
構造の確認
KNIMEで元のtest.smiと重複した構造(210化合物)を除くと,791個の新規構造が生成されていました.とりあえず化学構造式をPDFで出力して目で確認.
転移学習に使用したジテルペノイドの構造をそのまま反映した構造とそれとは関係のない元の学習済データ由来らしい構造がほとんどでしたが,ジテルペノイドの構造が少し変化したり融合したりした面白い構造もいくつか生成されていました.
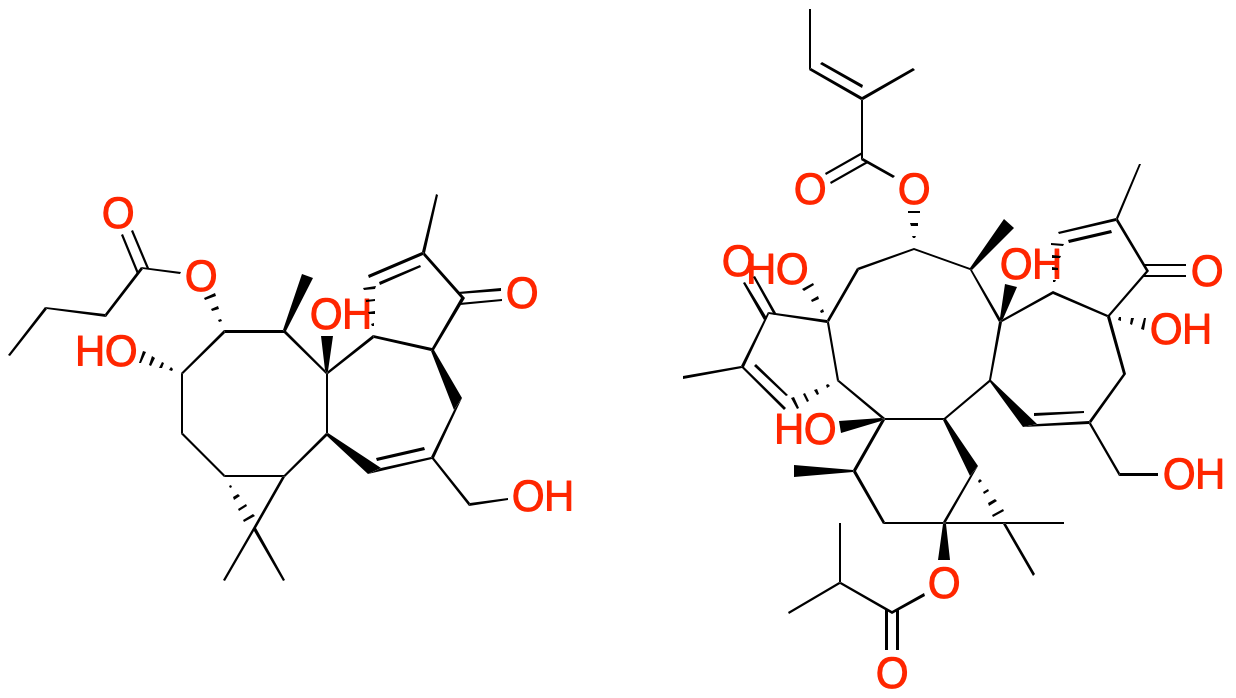
既知の生理活性天然物のファーマコフォアを別の骨格に移し換えるようなことが可能なら,面白いバーチャルライブラリになりそうですが,今のところそういったことは出来無さそうです.
次に読む論文
“Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules” Gómez-Bombarelli, R., et al., ACS Cent. Sci. 2018, 4, 268–276. DOI: 10.1021/acscentsci.7b00572
(了)